원글 : https://www.percona.com/blog/2020/03/26/sysbench-and-the-random-distribution-effect/
Sysbench and the Random Distribution Effect - Percona Database Performance Blog
How to customize sysbench to extend its use, with one way being the proper tuning of the random IDs generation.
www.percona.com
Sysbench의 난수 생성에 대해 알아야 할 사항
Sysbench는 벤치마킹을 수행하는 데 잘 알려져 있고 널리 사용되는 도구입니다. Peter Zaitsev가 2000 년 초에 처음 작성했으며 테스트 및 벤치마킹을 수행할 때 사실상 표준이 되었습니다. 요즘 Alexey Kopytov가 관리하며 https://github.com/akopytov/sysbench의 Github에서 찾을 수 있습니다.
What I have noticed though, is that while widely-used, some aspects of sysbench are not really familiar to many. For instance, the easy way to expand/modify the MySQL tests is using the lua extension, or the embedded way it handles the random number generation.
sysbench가 널리 사용되는 동안 일부 측면은 많은 사람들에게 실제로 익숙하지 않다는 것입니다. 예를 들어, MySQL 테스트를 확장/수정하는 쉬운 방법은 lua 확장 또는 난수 생성을 처리하는 내장된 방법을 사용하는 것입니다.
왜 이 기사일까요?
sysbench를 사용자 지정하여 필요한것을 쉽게 만들 수있는 방법을 보여주기 위해이 기사를 작성했습니다. sysbench 사용을 확장하는 방법에는 여러 가지가 있으며 그 중 하나는 임의 ID 생성을 적절히 조정하는 것입니다.
기본적으로 sysbench에는 난수를 생성하는 5가지 방법이 있습니다. 그러나 종종(실제로 거의 항상) 명시적으로 정의된것은 없으며, 방법이 허용할 때 매개 변수화를 보는 경우는 거의 없습니다.
“왜 관심을 가져야합니까? 대부분의 경우 기본값은 양호합니다.”좋습니다,이 블로그 게시물은 이것이 사실이 아닌 이유를 이해하는 데 도움을주기위한 것입니다.
시작해 봅니다.
sysbench에서 숫자를 생성하기 위해 어떤 방법을 사용할까요? 현재 다음이 구현되어 있으며 sysbench에서 –help 옵션을 호출하여 쉽게 확인할 수 있습니다.
- Special
- Gaussian
- Pareto
- Zipfian
- Uniform
그중에서 Special은 다음 매개 변수를 사용하는 기본값입니다.
- rand-spec-iter=12 – 특수 분포에 대한 반복 횟수 [12]
- rand-spec-pct=1 – '특별한'가치가 특별 분포에 속하는 전체 범위의 비율 [1]
- rand-spec-res=75 – 특별 분포에 사용할 '특수'값의 비율 [75]
간단하고 쉬운 재현 가능한 테스트 및 시나리오를 원한다면 sysbench 명령을 사용하여 다음 데이터를 모두 수집했습니다.
- sysbench ./src/lua/oltp_read.lua –mysql_storage_engine=innodb –db-driver=mysql –tables=10 –table_size=100 prepare
- sysbench ./src/lua/oltp_read_write.lua –db-driver=mysql –tables=10 –table_size=100 –skip_trx=off –report-interval=1 –mysql-ignore-errors=all –mysql_storage_engine=innodb –auto_inc=on –histogram –stats_format=csv –db-ps-mode=disable –threads=10 –time=60 –rand-type=XXX run
스크립트 명령 및 데이터를 통해 적절한 조합으로 원하는 테스트를 합니다.(https://github.com/Tusamarco/blogs/tree/master/sysbench_random).
sysbench는 난수 생성기로 무엇을할까요? 사용되는 방법 중 하나는 쿼리 생성에 사용할 ID를 생성하는 것입니다. 예를 들어, 각각 100 개의 행이있는 10 개의 테이블이있는 경우 1에서 100 사이의 숫자를 찾습니다.
위와 같이 sysbench RUN 명령을 실행하고 random –rand-type 만 변경하면 어떻게될까요?
스크립트를 실행하고 일반 로그를 사용하여 생성 된 ID를 수집 / 파싱하는 빈도를 알고 싶다면 이 테스트를 진행합니다.
| Special | |
| Uniform | |
| Zipfian | |
| Pareto | |
| Gaussian |
이해가 되나요? Sysbench는 기대했던 것과 정확히 일치합니다.
하나씩 확인하고 그에 대한 몇 가지 추론을하겠습니다.
Special
기본값은 Special이므로 사용할 임의 유형을 지정하지 않으면 sysbench는 special을 사용합니다. 특별한 것은 쿼리 작업에 매우 제한된 수의 ID를 사용하는 것입니다. 여기서 우리는 주로 ID 50-51을 사용하고 매우 산발적으로 44-56 사이의 세트를 사용하고 다른 것들은 실제로 관련이 없다고 말할 수 있습니다. 선택한 값은 사용 가능한 세트 1-100의 중간 범위에 있습니다.
이 경우 스파이크는 샘플의 2%를 나타내는 두 개의 ID에 집중됩니다. 레코드 수를 백만으로 늘리더라도 여전히 스파이크가 존재하며 샘플의 0.74 % 인 7493에 중점을 둡니다. 더 제한적이기 때문에 페이지 수는 아마 둘 이상일 것입니다.
Uniform
이름에서 알 수 있듯이 Uniform을 사용하면 모든 값이 ID에 사용되며 분포는… Uniform입니다.
Zipfian
Zipta 분포 (제타 분포라고도 함)는 언어, 보장 및 희귀 사건 모델링에 일반적으로 사용되는 불연속 분포입니다. 이 경우, sysbench는 더 낮은수 (1)부터 시작하여 더 큰 수를 향해 이동하면서 주파수를 매우 빠르게 줄입니다.
Pareto
80-20 규칙 (https://en.wikipedia.org/wiki/Pareto_distribution 참조)을 적용하는 Pareto를 사용하면 우리가 사용할 ID가 훨씬 덜 분산되고 소규모 세그먼트에 집중됩니다. 사용된 모든 ID의 52 %는 숫자 1을 사용하는 반면, 사용 된 ID의 73 %는 처음 10 개의 숫자에 있었습니다.
Gaussian
가우스 분포 (또는 정규 분포)는 잘 알려진대로 (https://en.wikipedia.org/wiki/Normal_distribution 참조) 주로 중심 요인에 대한 통계 및 예측에 사용됩니다. 이 경우 사용된 ID는 중간값에서 시작하여 벨 커브로 분산되고 가장자리쪽으로 천천히 감소합니다.
중요 요점은 무엇일까요?
위의 각 경우는 무언가를 나타내며, 그룹화하려면 파레토와 스페셜을 핫스팟에 집중할 수 있다고 말할 수 있습니다. 이 경우 응용 프로그램에서 동일한 페이지/데이터를 계속 사용하고 있습니다. 이것은 괜찮을 수 있지만, 현제 어떤 테스트를 하고 있는지 알아야 하며 실수로 끝나지 않도록해야합니다.
예를 들어, InnoDB 페이지 압축의 효율성을 읽기로 테스트하는 경우, 특수 또는 파레토 기본값을 사용하면 안됩니다. 즉, sysbench 기본값을 변경해야합니다. 이것은 1Tb의 데이터 세트와 30Gb의 버퍼 풀이 있고 동일한 페이지를 반복해서 쿼리하는 경우입니다. 해당 페이지는 이미 압축되지 않은 디스크의 메모리에서 읽었습니다.
요컨대, 테스트는 시간 / 노력 낭비입니다.
서면으로 효율성을 확인해야하는 경우에도 마찬가지입니다. 같은 페이지를 반복해서 쓰는 것은 좋은 방법이 아닙니다.
성능 테스트는 어떤가요?
다시 한 번, 성능을 파악하려고할때 어떤 경우에 다른 현상이 일어날까요? 다른 임의 유형을 사용하면 테스트에 큰 영향을 미칩니다. 따라서 “기본값으로 충분합니다"는 완전히 잘못된 것일 수 있습니다.
다음 그래프는 랜드 유형 값, 테스트 유형, 시간, 추가 옵션 및 스레드 수만 변경할 때 존재하는 차이점을 나타냅니다.
지연 시간은 유형마다 크게 다릅니다 :

여기서는 읽고 쓰는 작업을 수행했으며 데이터는 sys 스키마 (sys.schema_table_statistics)의 성능 스키마 쿼리에서 가져옵니다. 예상대로, 파레토와 스페셜은 시스템 (MySQL-InnoDB)이 인위적으로 하나의 핫스팟에서 경합을 겪고 있다는 점에서 다른 시스템보다 훨씬 오래 걸리고 있습니다.
rand-type을 변경하면 성능 스키마에 의해 보고된대로 대기 시간뿐만 아니라 처리된 행 수에도 영향을줍니다.
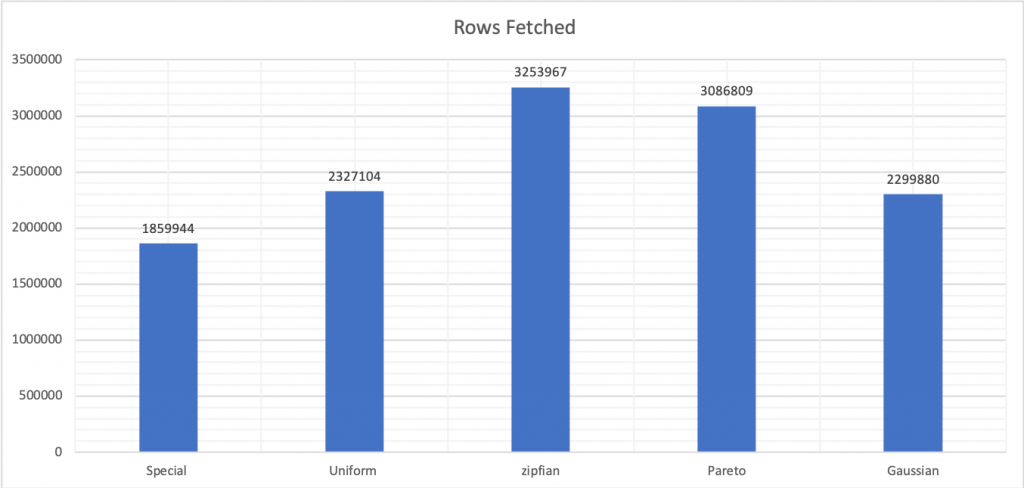
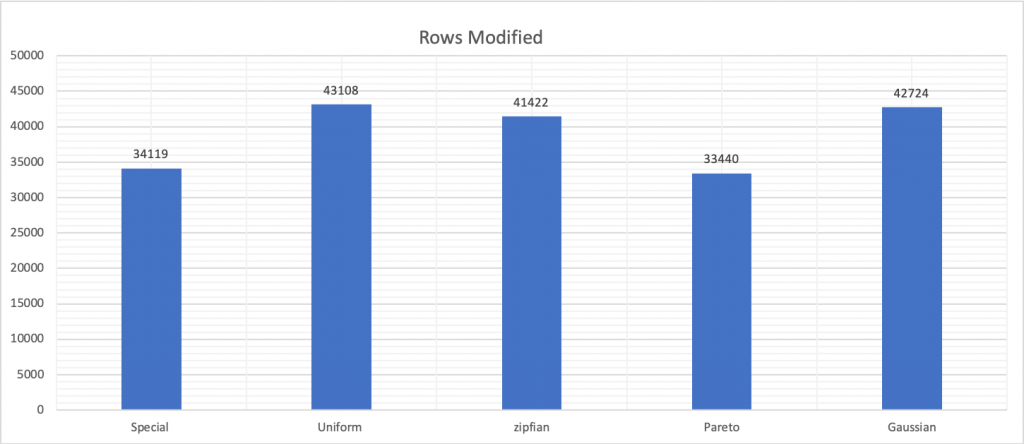
위의 모든 사항을 고려할때 테스트 대상을 명확히 분류하고 테스트하는것이 중요합니다.
테스트 범위가 시스템의 성능을 모든 수준에서 테스트하는 것이라면 데이터세트/DB서버/시스템에 읽기/로드/쓰기를 모든 곳에 동일하게 부하를 더 많이 줄 수 있는 Uniform을 사용하는 것이 좋습니다.
테스트 범위가 핫스팟을 처리하는 방법을 식별하는 것이라면 아마도 파레토와 스페셜이 올바른 선택 일 것입니다.
그러나 이 방법으로 테스트를 할때 기본값만 보면 안됩니다. 기본값은 좋지만 아마도 엣지 케이스를 재현하고있을 것입니다. 이것이 저의 개인적인 경험이며, 이 경우 매개 변수를 사용하여 올바르게 조정할 수 있습니다.
예를 들어, 중간 값을 사용하여 시스템 벤치 해머링을 유지하고 싶지만 간격을 완화하여 스파이크 (특수 기본값)는 아니지만 벨 커브 (가우시안)처럼 보이지 않도록 간격을 완화하려고합니다.
Special을 사용자 정의하고 다음과 같은 결과를 얻을 수 있습니다.

In this case, the IDs are still grouped and we still have possible contention, but less impact by a single hot-spot, so the range of possible contention is now on a set of IDs that can be on multiple pages, depending on the number of records by page.
이 경우 ID는 여전히 그룹화되어 있고 여전히 경합 가능성은 있지만 단일 핫스팟에 의한 영향은 적어, 페이지별 레코드 수에 따라 현재 가능한 경합 범위는 여러 페이지에 있을 수 있는 ID 세트에 있습니다.
또 다른 가능한 테스트 사례는 파티셔닝을 기반으로합니다. 예를 들어, 시스템이 파티션에서 작동하는 방식을 테스트하고 이전 라이브 데이터를 아카이브하면서 최신 라이브 데이터에 초점을 맞추려면 어떻게해야합니까?
쉽습니다! 파레토 분포의 그래프를 기억하십니까? 필요에 맞게 수정 할 수도 있습니다.

–rand-pareto 값을 조정하기 만하면 원하는 것을 정확하게 달성하고 sysbench가 더 높은 ID 값에 대한 쿼리에 집중할 수 있습니다.
Zipfian도 조정할 수 있으며 파레토와 마찬가지로 반전을 얻을 수는 없지만 하나의 값을 똑같이 분산하여 시나리오를 쉽게 분산시킬 수 있습니다. 좋은 예는 다음과 같습니다.

The last thing to keep in mind, and it looks to me that I am stating the obvious but better to say that than omit it, is that while you change the random specific parameters, the performance will also change.
마지막으로 명심해야 할 것은 분명하지만 생략하는 것보다 더 나은 말은 임의의 특정 매개 변수를 변경하는 동안 성능도 변경된다는 것입니다.
지연 시간 세부 정보 참조:
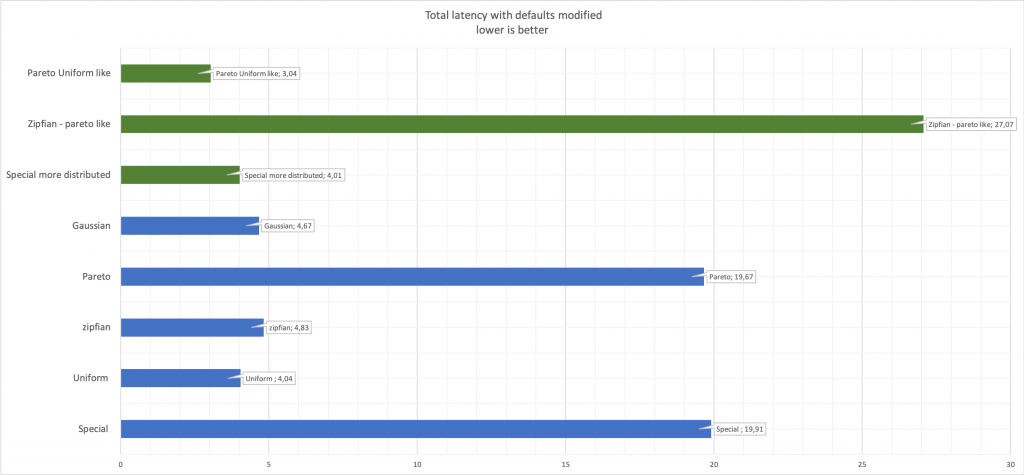
여기에서 수정된 값을 원본과 비교하여 파란색으로 녹색으로 볼 수 있습니다.
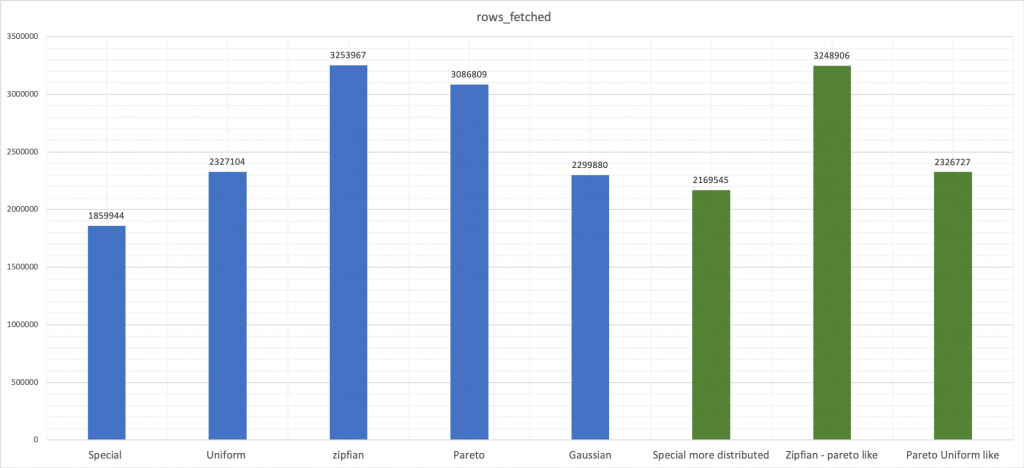
결론
At this point, you should have realized how easy it can be to adjust the way sysbench works/handles the random generation, and how effective it can be to match your needs. Keep in mind that what I have mentioned above is valid for any call like the following, such as when we use the sysbench.rand.default call:
이 시점에서, sysbench가 랜덤 생성을 발생하고/처리하는 방법을 얼마나 쉽게 조정할 수 있는지, 그리고 요구사항을 얼마나 효과적으로 충족시킬 수 있는지 알고 있어야합니다. 위에서 언급한 내용은 sysbench.rand.default 호출을 사용할 때와 같이 다음과 같은 모든 호출에 유효합니다.
local function get_id()
return sysbench.rand.default(1, sysbench.opt.table_size)
End테스트를 실행하기 전에 임의의 방법/설정을 확인하여 테스트 방법이 필요에 맞는지 확인합니다. 더 간단하게하기 위해 이 간단한 테스트를 사용합니다(https://github.com/Tusamarco/sysbench/blob/master/src/lua/test_random.lua). 테스트가 실행되고 ID 분포의 명확한 표현이 인쇄됩니다.
권장 사항은 테스트 요구에 맞는 것을 식별하고 올바른 방법으로 테스트/벤치마킹을 수행하는 것입니다.
참고
무엇보다도 Alexey Kopytov가 sysbench 작업에서 수행하고있는 위대한 작업을 참조하십시오. https://github.com/akopytov/sysbench
Zipfian 기사글:
Pareto:
Percona article on how to extend tests in sysbench
The whole set of material I used for this article is on GitHub (https://github.com/Tusamarco/blogs/tree/master/sysbench_random)
※도움이 되셨다면 광고클릭 한번 부탁드립니다.※
'Databases > MySQL' 카테고리의 다른 글
| [MySQL][InnoDB] 모니터 (0) | 2020.07.20 |
|---|---|
| [MySQL][InnoDB] 성능 스키마와 InnoDB 통합 (0) | 2020.07.19 |
| [Performance] Sysbench 설치 및 사용방법 (0) | 2020.07.12 |
| [MySQL][InnoDB] Deadlock (0) | 2020.07.07 |
| [MySQL][InnoDB] InnoDB에서 다른 SQL 문으로 설정된 잠금 (0) | 2020.07.02 |